How Sovel finds and fixes
knowledge risk
The Sovel method is detection-led, reviewer-governed, and outcome-tracked. This page explains the logic, the rules, and the loop — from raw work order data to a placed operational knowledge object.
Detect → Capture → Govern → Place → Monitor
Detect
Gap engine scans WO history. Issues ranked by severity and risk type.
Capture
Technicians contribute context via voice or text when a WO ties to a flagged issue.
Govern
Reviewers approve, edit, or reject AI-structured drafts. Nothing advances without sign-off.
Place
Approved knowledge becomes a versioned Operations Skill bound to the maintenance ontology.
Monitor
Placement reduces issue risk. MTTR and response-time improvements close the ROI loop.
Six rules that find what your CMMS misses
Sovel does not require any modification to your CMMS. It reads a standard work order export and applies six detection rules. Each rule produces prioritized issues with a severity score, confidence estimate, and linked evidence.
Recurring failures
Work orders for the same asset and failure mode that close without documented root cause or resolution steps. Repeated corrective work with no captured fix signals undocumented expertise.
Knowledge concentration
Critical assets handled predominantly by one or two technicians, with measurable resolution-time gaps when they are absent. Concentration risk is scored against coverage breadth and expert tenure proximity.
Procedure drift
WO descriptions diverge from the documented procedure for the same task. Drift flags where field practice has evolved away from written SOPs — sometimes a quality risk, sometimes a smarter field adaptation that should update the procedure.
High-cost blind spots
High labor cost or high downtime assets that lack documented troubleshooting coverage. The combination of maintenance spend and knowledge gap represents the highest marginal value of capture.
Retirement risk
Long-tenured experts holding concentrated knowledge on critical assets. When tenure is high and coverage is narrow, each day without capture is a shrinking window. Retirement risk issues are prioritized for immediate capture outreach.
Shadow work
Undocumented workarounds that show up in WO narratives but never make it into official procedures. Shadow work often represents the real institutional knowledge — the informal fix that works when the manual approach fails.
Reviewers decide. Models surface.
Sovel may use language models for structured extraction, similarity scoring, and assistive evidence summarization. The product stance is consistent: reviewers decide. Sign-off, safety culture, and your change process stay with your people and procedures.
- Structured drafts, not decisions. The AI produces a draft knowledge entry with source citations. The reviewer reads, edits, and approves — or rejects.
- Immutable audit trail. Every approval, edit, and rejection is logged with timestamp, author, and reason code. The full decision chain is discoverable in any audit.
- Contradiction detection. When a new entry conflicts with an existing Operations Skill, a propagation alert surfaces the conflict. Reviewers resolve it; the AI does not auto-overwrite.
- Correction inference. Over time, the reviewer's editing patterns inform which extraction dimensions need improvement — improving future drafts without overriding human authority.
Federation: pattern shapes, never entity data
Every reviewer-approved decision at one plant sharpens the detection model at every other plant in the network — without any customer name, asset tag, telemetry value, or entry body crossing the boundary. Opt-in, one-way hashed, and gated behind a legal data-sharing agreement.
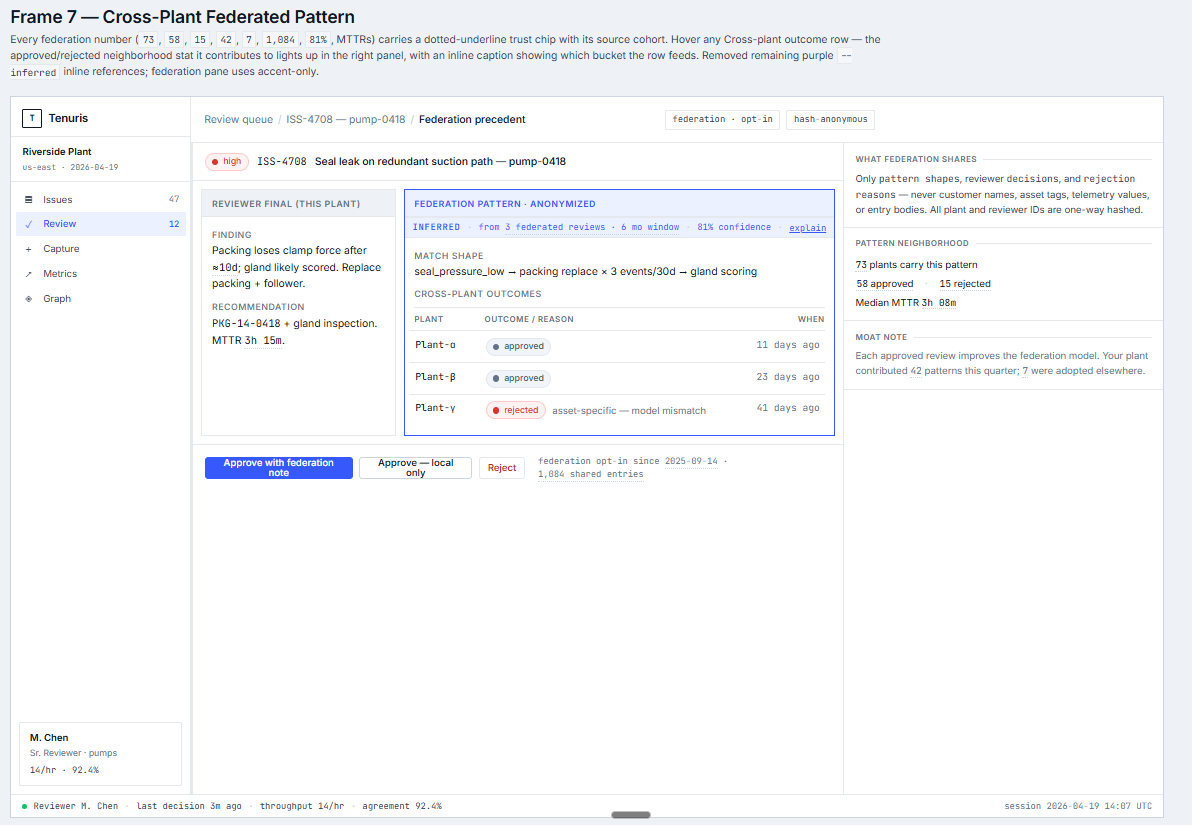
- ✓ Anonymized pattern shapes
- ✓ Reviewer decisions + rejection reasons
- ✓ One-way-hashed plant + reviewer IDs
- ✗ Customer or facility names
- ✗ Asset identifiers, serial numbers, telemetry
- ✗ Raw reviewer-entry bodies
Category-defining detection surfaces
Four long-form explanations of how Sovel detects, gates, and benchmarks specific knowledge-risk archetypes. Written for reliability engineers, maintenance directors, and plant managers who want the reasoning, not the pitch.
Operator-overridden setpoint detection
Measurement-and-verification literature has named operator-overridden setpoints as a leading cause of persistent drift in industrial and building systems for two decades. Sensor-first fault detection can see the override; it cannot see the reasoning that produced it.
Shift-handover gap surface
Across the plant-incident research corpus, more than forty percent of incidents originate at shift change. The cause named repeatedly is not a lack of people — it is a drop in situational awareness as the outgoing shift's interventions, workarounds, and unresolved issues fail to reach the incoming shift with enough context to matter.
ROI-gated issue prioritization
An issue backlog that surfaces everything surfaces nothing. The detection engine can find thousands of knowledge risks in a mature plant's work-order history, and will, if unchecked.
Offline evaluation harness
Most vertical-AI products benchmark on synthetic tasks. Industrial maintenance has a decade of published academic work that has already labeled maintenance text at scale — FMUCD, MaintKG, MaintIE, MaintNet, the Baltimore PM corpus — and has done the taxonomy work to make precision and recall measurable against real work-order narratives.
How Sovel Compounds.
- Provenance per inference
Every suggestion carries cited sources, model version, confidence, and reviewer history.
- Immutable audit trail
Every decision — accept, edit, reject — is recorded with reason code and reviewer identity.
- Reviewer is final governor
No autonomous commits to governed truth. Humans decide; Sovel remembers.
- Inferred from your corrections
The Correction Inference Engine personalizes suggestions based on each reviewer's history.
- Knowledge-governance-first
Detection, capture, governance, placement, monitoring — designed as one continuous loop.
Industrial-governance HITL patterns we implement
Five patterns identified as the 2026 state-of-practice for safe LLM use in regulated industrial workflows. All five are scaffolded in Sovel today. The architecture is not novel by accident — it matches what serious operators are converging on.
Structured side-effect blocks
Every governed write is a typed, content-hashed JSON object — never free-text into production. Reviewer sees the structure before placement.
Bounded auto-retry before human handoff
The AI co-reviewer attempts a finite number of retrieval and refinement passes, then yields to the human gate. No infinite loops, no silent failures.
Dry-run / approval gates on every governed write
No autonomous commits to governed knowledge. Ever. Reviewer is the final governor of what becomes operational truth.
Append-only audit logs
Model version, confidence, cited sources, reviewer identity, timestamp — captured per inference, never mutated. The regulator-audit-ready substrate.
Drift scanning
Freshness/decay signals + contradiction detection continuously surface entries whose context has shifted, so the governed knowledge base does not silently rot.
Why our architectural choices look like 2026 best practice
The CIE design did not emerge in a vacuum. It matches what published 2026 research is converging on for safe HITL governance in regulated industrial workflows.
LangGraph contained inside the provider boundary
We deliberately keep LangGraph inside the CorrectionInferenceProvider rather than exposing it as the app-level orchestrator. This sidesteps the LangMem p95 latency trap (59.82s reported in published benchmarks vs Mem0's 0.200s) and keeps the reviewer experience snappy.
Operational metrics over synthetic benchmarks
We measure FirstPassRate, Validation Convergence, and MTTR lift on governed assets — not Codeforces-style scores. Published research (the "SWE-Bench Illusion" finding) documents 23–25% real-world collapse from synthetic benchmark scores.
Plan-then-Execute UX paradigm
The 2026 industry pattern for HITL governance: AI proposes a structured plan, the human pressure-tests and governs. Sovel's reviewer workflow is a Plan-then-Execute system by construction — every governed write goes through human approval.
Causal inference for AI-inferred edges
When the engine proposes a relationship in the knowledge graph, we hold it in a governed-edge proposal queue rather than auto-committing. Published methodology (DoWhy: Model → Identify → Estimate → Refute) provides the validation pattern; reviewer judgment provides the final governance.
The atomic unit of governed knowledge
An Operations Skill is a governed, versioned knowledge object that pairs a specific failure mode and asset context with structured resolution guidance and provenance. It is the output of the Govern → Place step and the query target during operations.
A typed graph of what you know
Operations Skills are placed into a Maintenance Ontology — a typed graph connecting assets, failure modes, experts, and governed knowledge. The ontology enables relationship queries ("what breaks if Tom retires?") that raw WO history cannot answer.
Every skill placed in the ontology creates a provenance edge. The graph shows which experts hold knowledge for which assets — and how that coverage changes as people retire or are transferred.
When a new skill conflicts with an existing ontology node, the system flags the contradiction before placement — forcing reviewers to adjudicate rather than silently overwriting organizational memory.
Skills decay in confidence over time without revalidation. The lint loop surfaces stale entries for reviewer attention — preventing governed knowledge from drifting out of date silently.
See it run on your data.
Share a 6-month work order export from one asset area. We run the gap engine and return a ranked list of issues specific to your plant — in 48 hours.